#FactCheck: Viral Video of Chandra Arya Speaking Kannada Unrelated to Canadian PM Nomination
Executive Summary:
Recently, our team encountered a post on X (formerly Twitter) pretending Chandra Arya, a Member of Parliament of Canada is speaking in Kannada and this video surfaced after he filed his nomination for the much-coveted position of Prime Minister of Canada. The video has taken the internet by storm and is being discussed as much as words can be. In this report, we shall consider the legitimacy of the above claim by examining the content of the video, timing and verifying information from reliable sources.

Claim:
The viral video claims Chandra Arya spoke Kannada after filing his nomination for the Canadian Prime Minister position in 2025, after the resignation of Justin Trudeau.

Fact Check:
Upon receiving the video, we performed a reverse image search of the key frames extracted from the video, we found that the video has no connection to any nominations for the Canadian Prime Minister position.Instead, we found that it was an old video of his speech in the Canadian Parliament in 2022. Simultaneously, an old post from the X (Twitter) handle of Mr. Arya’s account was posted at 12:19 AM, May 20, 2022, which clarifies that the speech has no link with the PM Candidature post in the Canadian Parliament.
Further our research led us to a YouTube video posted on a verified channel of Hindustan Times dated 20th May 2022 with a caption -
“India-born Canadian MP Chandra Arya is winning hearts online after a video of his speech at the Canadian Parliament in Kannada went viral. Arya delivered a speech in his mother tongue - Kannada. Arya, who represents the electoral district of Nepean, Ontario, in the House of Commons, the lower house of Canada, tweeted a video of his address, saying Kannada is a beautiful language spoken by about five crore people. He said that this is the first time when Kannada is spoken in any Parliament outside India. Netizens including politicians have lauded Arya for the video.”

Conclusion:
The viral video claiming that Chandra Arya spoke in Kannada after filing his nomination for the Canadian Prime Minister position in 2025 is completely false. The video, dated May 2022, shows Chandra Arya delivering an address in Kannada in the Canadian Parliament, unrelated to any political nominations or events concerning the Prime Minister's post. This incident highlights the need for thorough fact-checking and verifying information from credible sources before sharing.
- Claim: Misleading Claim About Chandra Arya’s PM Candidacy
- Claimed on: X (Formerly Known As Twitter)
- Fact Check: False and Misleading
Related Blogs

Executive Summary:
On 20th May, 2024, Iranian President Ebrahim Raisi and several others died in a helicopter crash that occurred northwest of Iran. The images circulated on social media claiming to show the crash site, are found to be false. CyberPeace Research Team’s investigation revealed that these images show the wreckage of a training plane crash in Iran's Mazandaran province in 2019 or 2020. Reverse image searches and confirmations from Tehran-based Rokna Press and Ten News verified that the viral images originated from an incident involving a police force's two-seater training plane, not the recent helicopter crash.
Claims:
The images circulating on social media claim to show the site of Iranian President Ebrahim Raisi's helicopter crash.



Fact Check:
After receiving the posts, we reverse-searched each of the images and found a link to the 2020 Air Crash incident, except for the blue plane that can be seen in the viral image. We found a website where they uploaded the viral plane crash images on April 22, 2020.

According to the website, a police training plane crashed in the forests of Mazandaran, Swan Motel. We also found the images on another Iran News media outlet named, ‘Ten News’.
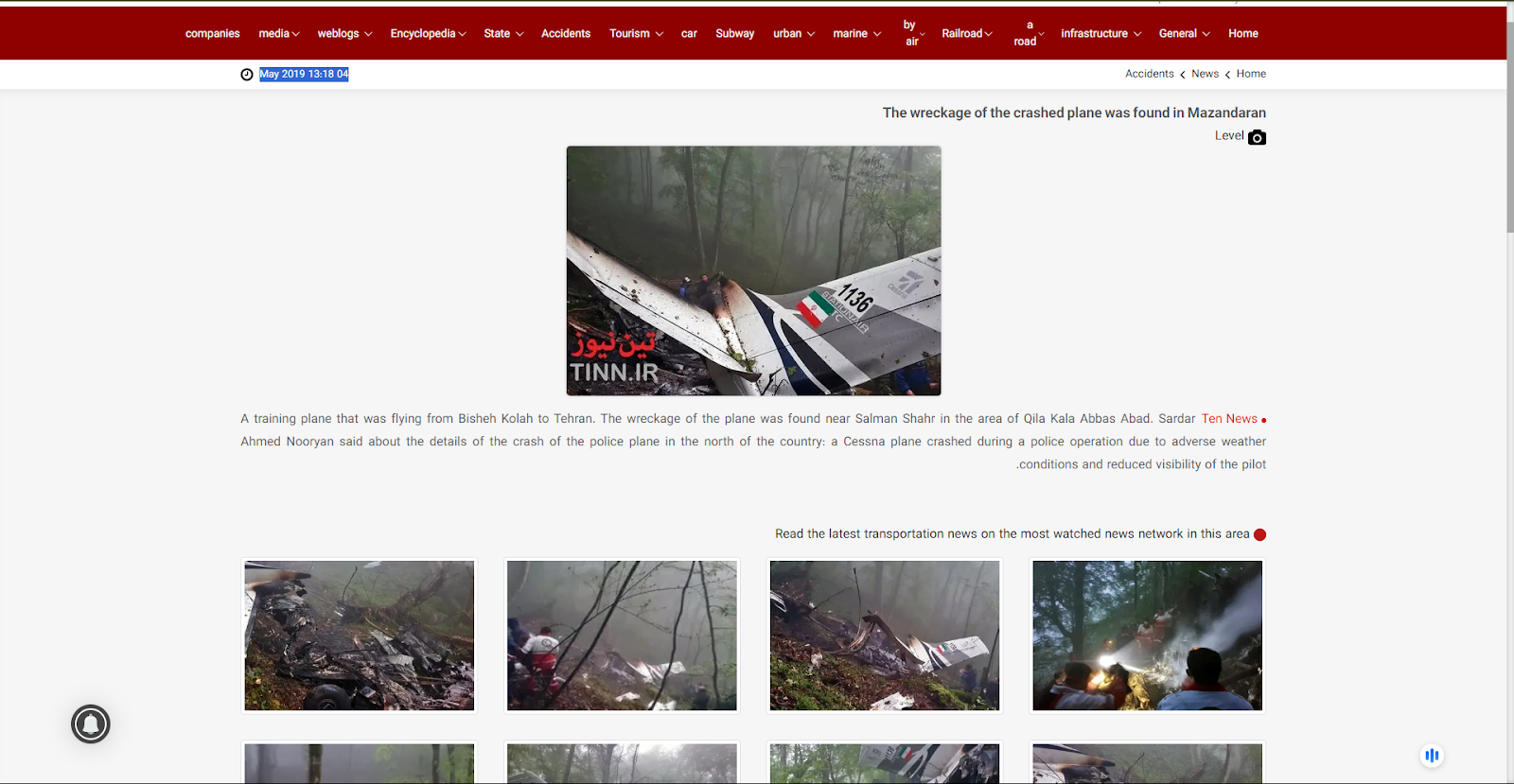
The Photos uploaded on to this website were posted in May 2019. The news reads, “A training plane that was flying from Bisheh Kolah to Tehran. The wreckage of the plane was found near Salman Shahr in the area of Qila Kala Abbas Abad.”
Hence, we concluded that the recent viral photos are not of Iranian President Ebrahim Raisi's Chopper Crash, It’s false and Misleading.
Conclusion:
The images being shared on social media as evidence of the helicopter crash involving Iranian President Ebrahim Raisi are incorrectly shown. They actually show the aftermath of a training plane crash that occurred in Mazandaran province in 2019 or 2020 which is uncertain. This has been confirmed through reverse image searches that traced the images back to their original publication by Rokna Press and Ten News. Consequently, the claim that these images are from the site of President Ebrahim Raisi's helicopter crash is false and Misleading.
- Claim: Viral images of Iranian President Raisi's fatal chopper crash.
- Claimed on: X (Formerly known as Twitter), YouTube, Instagram
- Fact Check: Fake & Misleading

Executive Summary
A video of Uttar Pradesh Chief Minister Yogi Adityanath is being widely circulated on social media with the claim that he supported the Bihar police and justified the encounter of Bharat Bhushan Tiwari in Bhojpur district’s Bilouti village on June 17, 2026. CyberPeace Research Wing research found the claim to be misleading. The viral video is not related to the Bihar encounter case. It is an old video from February 2026, in which the Chief Minister was speaking in the context of law and order and police action in Uttar Pradesh.
Claim:
A Facebook user shared the video claiming it shows CM Yogi Adityanath’s reaction supporting the Bihar encounter of Bharat Tiwari. https://www.facebook.com/reel/1712174420025092 ,https://archive.ph/wip/yUsou

Fact Check:
A keyword search led to the same video being found on the ‘ET Now Swadesh’ YouTube channel in the form of a short video, uploaded on February 4, 2026, indicating that it predates the Bihar incident. https://www.youtube.com/watch?v=Dj7ySFsnkqk

Further verification led to a Dainik Jagran report published on February 3, 2026, which carried visuals from the same statement. The report confirmed that the remarks were made in the context of Uttar Pradesh’s law and order situation and police response. https://www.jagran.com/uttar-pradesh/lucknow-city-cm-yogi-on-up-crime-zero-tolerance-and-police-action-justified-40129630.html
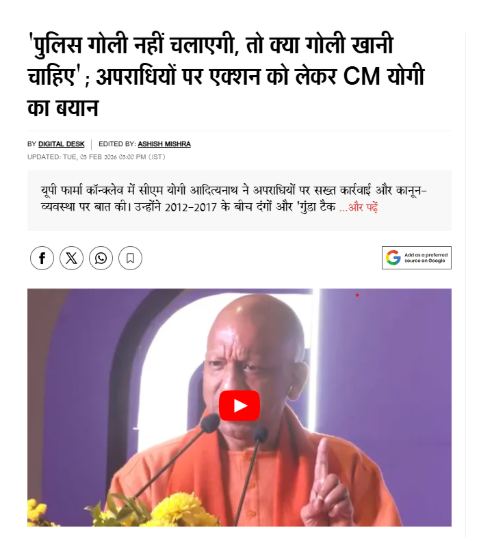
The report quoted CM Yogi Adityanath saying that if police do not act, criminals would dominate the situation, and that police are empowered to respond in the language criminals understand. He also emphasized that police training is designed to ensure effective response to crime. An Aaj Tak report on the Bihar encounter case stated that 28-year-old Bharat Tiwari was killed in an encounter on June 17, 2026, in Bhojpur district. Following the incident, an FIR was registered against police personnel, and the victim’s mother demanded strict action and justice.
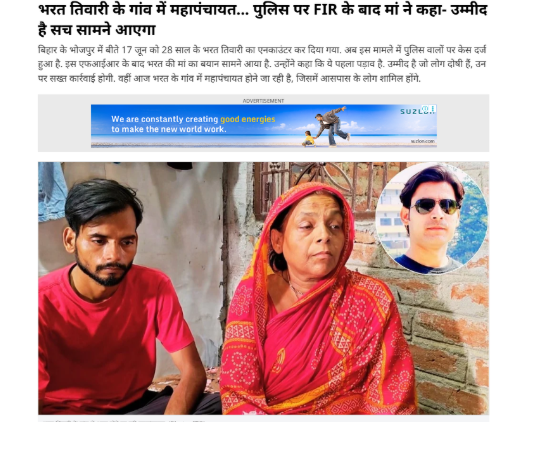
Conclusion:
The research confirms that the viral video of CM Yogi Adityanath is old and unrelated to the Bihar encounter case. It is from February 2026 and pertains to a law-and-order statement in Uttar Pradesh. The video is being falsely shared by linking it to the Bihar encounter incident.

Executive Summary:
A viral post currently circulating on various social media platforms claims that Reliance Jio is offering a ₹700 Holi gift to its users, accompanied by a link for individuals to claim the offer. This post has gained significant traction, with many users engaging in it in good faith, believing it to be a legitimate promotional offer. However, after careful investigation, it has been confirmed that this post is, in fact, a phishing scam designed to steal personal and financial information from unsuspecting users. This report seeks to examine the facts surrounding the viral claim, confirm its fraudulent nature, and provide recommendations to minimize the risk of falling victim to such scams.
Claim:
Reliance Jio is offering a ₹700 reward as part of a Holi promotional campaign, accessible through a shared link.

Fact Check:
Upon review, it has been verified that this claim is misleading. Reliance Jio has not provided any promo deal for Holi at this time. The Link being forwarded is considered a phishing scam to steal personal and financial user details. There are no reports of this promo offer on Jio’s official website or verified social media accounts. The URL included in the message does not end in the official Jio domain, indicating a fake website. The website requests for the personal information of individuals so that it could be used for unethical cyber crime activities. Additionally, we checked the link with the ScamAdviser website, which flagged it as suspicious and unsafe.


Conclusion:
The viral post claiming that Reliance Jio is offering a ₹700 Holi gift is a phishing scam. There is no legitimate offer from Jio, and the link provided leads to a fraudulent website designed to steal personal and financial information. Users are advised not to click on the link and to report any suspicious content. Always verify promotions through official channels to protect personal data from cybercriminal activities.
- Claim: Users can claim ₹700 by participating in Jio's Holi offer.
- Claimed On: Social Media
- Fact Check: False and Misleading