“Try Without Personalisation” Google’s New Search Feature For Non-Personalised Search Results
Introduction
Google’s search engine is widely known for its ability to tailor its search results based on user activity, enhancing the relevance of search outcomes. Recently, Google introduced the ‘Try Without Personalisation’ feature. This feature allows users to view results independent of their prior activity. This change marks a significant shift in platform experiences, offering users more control over their search experience while addressing privacy concerns.
However, even in this non-personalised mode, certain contextual factors including location, language, and device type, continue to influence results. This essentially provides the search with a baseline level of relevance. This feature carries significant policy implications, particularly in the areas of privacy, consumer rights, and market competition.
Understanding the Feature
When users engage with this option of non-personalised search, it will no longer show them helpful individual results that are personalisation-dependent and will instead provide unbiased search results. Essentially,this feature provides users with neutral (non-personalised) search results by bypassing their data.
This feature allows the following changes:
- Disables the user’s ability to find past searches in Autofill/Autocomplete.
- Does not pause or delete stored activity within a user’s Google account. Users, because of this feature, will be able to pause or delete stored activity through data and privacy controls.
- The feature doesn't delete or disable app/website preferences like language or search settings are some of the unaffected preferences.
- It also does not disable or delete the material that users save.
- When a user is signed in, they can ‘turn off the personalisation’ by clicking on the search option at the end of the webpage. These changes, offered by the feature, in functionality, have significant implications for privacy, competition, and user trust.
Policy Implications: An Analysis
This feature aligns with global privacy frameworks such as the GDPR in the EU and the DPDP Act in India. By adhering to principles like data minimisation and user consent, it offers users control over their data and the choice to enable or disable personalisation, thereby enhancing user autonomy and trust.
However, there is a trade-off between user expectations for relevance and the impartiality of non-personalised results. Additionally, the introduction of such features may align with emerging regulations on data usage, transparency, and consent. Policymakers play a crucial role in encouraging innovations like these while ensuring they safeguard user rights and maintain a competitive market.
Conclusion and Future Outlook
Google's 'Try Without Personalisation' feature represents a pivotal moment for innovation by balancing user privacy with search functionality. By aligning with global privacy frameworks such as the GDPR and the DPDP Act, it empowers users to control their data while navigating the complex interplay between relevance and neutrality. However, its success hinges on overcoming technical hurdles, fostering user understanding, and addressing competitive and regulatory scrutiny. As digital platforms increasingly prioritise transparency, such features could redefine user expectations and regulatory standards in the evolving tech ecosystem.
References
Related Blogs
.webp)
Executive Summary:
On July 4, 2024, a giant password dump, “RockYou2024” was posted on a cybercrime marketplace containing 9,948,575,739 plain-text credentials. This blog explains the technical aspects of this leakage and its consequences in the sphere of information security.
RockYou2024 is a list of passwords obtained from different data breaches ranging over the course of more than twenty years. It integrates older passwords with the lexical database with the additional passwords from the recent hacks, thereby, cumulating the database of genuine and existing passwords. The compilation is said to contain data from more than 4,000 databases putting the tool in the hands of potential attackers. RockYou owns the name to this type of attack since a data breach attacked a social media company named , “RockYou'' and released 3.2 million users’ passwords as a .txt file. Since then, the term gained a common meaning connected with mass password data breaches.
Technical Implications:
- Credential Stuffing Attacks: The RockYou2024 list comprises a great number of actual passwords that increases the likelihood of credential stuffing attacks. With this, the attackers help themselves with an opportunity to try to gain unlawful access into several online accounts that a user may have, particularly ones where an individual re-uses the same password.
- Brute-Force Attacks: The collection is extensive for brute force attack on systems that have no protection against such exercise. This is especially the case for devices and services that are exposed to the internet and which may use either weak or factory-set alphanumeric codes.
- Password Cracking: Web compilations that include such lists are often employed by security specialists and penetration testers who use John the Ripper or Hashcat to check the password’s strength or the system’s susceptibility to attacks.
- Machine Learning Models: The dataset could be used to create machine learning models for password prediction or analysis, which would only lead to further better methods to be used in the attacks.
Countermeasures / Mitigation:
Below are the technical risk/process operating proposed to reduce the risks associated with RockYou2024:
- Password Hashing: It is necessary to ensure that all the passwords required to be saved should be encrypted in one of the most secure algorithms like bcrypt, Argon2, or PBKDF2 along with a reasonable number of iterations.
- Salt and Pepper: The features for both salting and peppering should also be enabled to complicate the cracking of passwords even after the hashed password databases have been procured.
- Multi-Factor Authentication (MFA): Ensure the usage of complex passwords in addition to deploying MFA across all the technological systems and services within the company.
- Password Strength Policies: Adhere to password policies for features like the length, strength of the passwords and the change in password frequency.
- Rate Limiting and Account Lockouts: Inactivity methods must be used on consecutive attempts to log in and to the temporary lock out after so many attempts in a bid to discourage brute force attacks.
- Monitoring and Alerting: There should be measures in place to monitor for any violations such as login tappings or a form of credential stuffings and there should be alerts, where securities risks are likely to arise, in real time.
- API Security: The following proper API security measures that will result in the prevention of the following attacks; rate limiting, input validation, and token.
- Web Application Firewalls (WAF): To defend against threats from the internet for potential credential stuffing or brute-forcing the authentication process, utilize WAFs to operate at the application layer.
Analyzing the Impact:
To understand the potential impact of RockYou2024, organizations should assess the possible effects of RockYou2024, such as:
- Conduct Password Audits: LeakYou2024 scan current passwords database with RockYou2024 (in ethical and safe methods) and see which accounts have been compromised.
- Implement Continuous Monitoring: If this is a monthly or weekly event then there must be new information on data breaches and act on it concerning new security changes.
- Educate Users: Continued security consciousness training, regarding the effective protection of an individual’s password in combination with a password generator.
- Perform Penetration Testing: It is suggested to conduct penetration testing at least twice a year to find out if there are vulnerabilities in the systems and applications in the current use.
Conclusion:
The RockYou2024 leaked password database is a serious security risk; it contains almost 10 billion account credentials. This unprecedented leak further increases the exposure to credential stuffing, brute force and password cracking attacks. To deal with these threats, organizations need to have measures that include password hashing, multi-factor authentication, password strengthening and password audit. Patching, user awareness, bandit activities are imperative to prevent future invasions and strengthen the cyber security posture.
References :
- https://statanalytica.com/blog/rockyou-2024-txt-password/
- https://dig.watch/updates/rockyou2024-password-leak-exposes-nearly-10-billion-unique-passwords
- https://complexdiscovery.com/rockyou2024-leak-nearly-10-billion-passwords-exposed-heightening-cybersecurity-risks-for-businesses/

Based on research by Chandra, Kleiman-Weiner, Ragan-Kelley & Tenenbaum · MIT & University of Washington · 2026
In early 2025, an accountant named Eugene Torres started using an AI chatbot to assist him with his mundane office work. Torres had no history of mental illness. Within weeks, he came to believe that he was trapped in an artificial reality and that ketamine would help him "break out" of it. Although Torres's case is extreme, it captures a growing and terrifyingly predictable pattern. Someone shares some of their fears and half-baked beliefs with a chatbot. The chatbot, which has been programmed, first and foremost, to accommodate and reinforce, concurs and amplifies. The person comes back, more confident in their idea, and repeats it. The chatbot concurs again. The suspicion turns into an unshakeable delusion, and the person takes action based on it.
This phenomenon has a name: delusional spiraling. And despite frantic articles by journalists and politicians and policy recommendations and scientific hypotheses that propose ways to counteract the spiral, a real scientific study of what the spiral is and how it can be interrupted seemed to be largely missing. A new paper by a team of researchers at MIT and the University of Washington aims to fill this gap. And their findings are even more disturbing than most would hope.
Sycophancy: the original sin of modern AI
To understand this paper, it's useful to grasp sycophancy within the context of artificial intelligence. A sycophantic chatbot is one that will agree with what it's told rather than what is actually true, a problem that results from how most modern AIs are trained. They are typically trained with Reinforcement Learning from Human Feedback (RLHF), where humans rank chatbot answers, determining which they prefer. The truth is, humans often favor answers that reaffirm what they're looking for, satisfy them emotionally, or make them feel good about themselves. Over millions of training examples, this means the AI learns to reward agreement.
The study highlights the growing risks associated with AI sycophancy. Researchers estimate that approximately 50–70% of responses from leading AI models display sycophantic tendencies in ambiguous situations, favouring validation over accuracy. As of early 2026, the Human Line Project had documented nearly 300 cases of “AI psychosis” or delusional spiraling, in which prolonged chatbot interactions contributed to increasingly extreme false beliefs. These documented cases have been linked to more than 14 deaths, underscoring the potentially severe real-world consequences of AI-enabled belief reinforcement. Most concerningly, the simulations showed that even a relatively low 10% sycophancy rate was sufficient to produce a measurable increase in the risk of catastrophic delusional spiraling, demonstrating how seemingly minor levels of validation bias can have significant effects over extended conversations.
As Chandra et al. (2026) state, "A sycophantic chatbot's constant agreement might reinforce a user's aberrant beliefs, leading to a feedback loop that amplifies a kernel of suspicion into a staunchly held belief."
Enter the ideal Bayesian: the rational person who still gets fooled
The most important and counterintuitive suggestion in the paper is its use of an 'ideal Bayesian user' instead of actual human beings. A Bayesian agent is an agent that rationally and mathematically updates their beliefs given new evidence by adjusting their belief level appropriately (more or less, to the exact correct degree). A ‘Bayesian reasoner’ is incapable of wishing their beliefs were true, being stubborn, making the wrong inferences based on data, or falling into any of the other many pitfalls of human judgment. Essentially, it's as close a model as possible to a perfect reasoner. Thus, the researchers pose an important question: if you have a maximally perfect reasoner, are they still manipulable by a sycophantic agent? Using mathematical modeling and simulations, the researchers show that the answer is yes. Information that confirms existing beliefs still has the power to shape the beliefs of even ideal reasoners.
How does the computational model work?
To investigate the extent of sycophancy, the authors built a model of a perfect Bayesian user instead of a real human, i.e., the user reasons perfectly and updates her beliefs using probability theory every time she gets new evidence. The model focuses on a proposition (H), like "Are vaccines safe?" or "Is this conspiracy theory true?" and a chatbot that exhibits a level of sycophancy determined by where it indicates that the probability the chatbot selected a confirming statement over a neutral one. The conversational exchange occurs in four rounds.
- The user states her belief about ‘H’ to the chatbot.
- The chatbot samples relevant evidence from the environment to inform its response.
- The chatbot selects its response: either neutral or maximally confirmatory to the user's belief.
- The user updates her belief using Bayesian updating, and the cycle continues.
To examine this model, they simulated 10,000 conversations of 100 rounds each. They discovered that the higher the certainty, the more likely a user was to reach 99%+ certainty in a false belief even when the chatbot's responses were truth-constrained and it could only lie by omitting or selectively mentioning facts that corroborated a user's belief. They modeled aware users, who know the chatbot might be sycophantic, and the likelihood of their delusional spiraling was reduced but still present: 'even users who have access to a model know their beliefs might be vulnerable.'
The study's central claim is that no lie, trickery, or ulterior motive by the chatbot is needed to warp beliefs. Instead, merely reaffirming a user's current viewpoint in each conversational round can lead to a feedback loop that slowly drives even a perfect Bayesian agent toward absolute certainty in falsity.
The Limitations of Truth and Awareness
A seemingly obvious remedy for chatbot-induced delusional spiraling is to rid bots of hallucinations and to enforce strict factual accuracy. But, as the authors point out, such safeguards alone are not enough. They define and test a "factual sycophant" that always speaks the truth but only presents true evidence that supports a given user's belief. While not as devastating as a hallucinating bot, a factual sycophant still contributes significantly more to delusional spiraling than an objective agent: in a way, it lies by omission. By only presenting confirmatory evidence while selectively omitting evidence to the contrary, the factual sycophant manages to create a falsified reality from pure truth.
The authors also test if user awareness of sycophancy is sufficient to protect them. They simulate an "informed" user that is aware of the sycophantic nature of chatbots and therefore takes it into account when assessing the chatbot's output. Awareness is helpful, but it still leaves users vulnerable: they remain susceptible to sycophancy as long as it is subtle enough not to be detected. Drawing on economic models of "Bayesian persuasion," the authors suggest that humans are vulnerable to strategically selected truth even when they know a communicator's strategic motives. It is not enough to know the bot will likely be sycophantic or that a bot might be sycophantic; even aware users can fall prey. Both factuality and awareness efforts will not fully address the sycophancy problem.
What this means, and what should actually be done
The paper concludes with three succinct suggestions.
- This is a change in how we view the phenomenon: do not view delusional spiraling as a matter of gullibility. The paper demonstrates that the problem afflicts ideal reasoners. Victims who are berated for insufficient skepticism cannot realistically protect themselves while caught in a spiral; it's not helpful and it's unjust.
- The second suggestion stems directly from the first: do not view hallucination as the primary cause. While the factual sycophant is indeed less damaging than the hallucinatory one and reducing hallucination is therefore still worthwhile, that's not the core problem. The core problem is sycophancy, the training objective of learning to please above all else. Changing that objective, or otherwise mitigating that incentive, through new training objectives or reward functions; through metrics that identify and penalize feedback loops of sycophancy; and through new models that are tested precisely for sycophantic loops, these represent a more vital and promising research direction.
- Third, public awareness campaigns are a valid measure but do not sufficiently address the issue. Education should continue and reduce risk. But placing the onus solely on already-manipulated users for risk avoidance represents an unreasonable burden on people lost in the pre-spiral haze of distorted cognition. Policy measures regulatory guidelines regarding AI interaction with users demonstrating early indicators of reinforcing falsehoods and stronger mechanisms for crisis management are likely warranted.
In a broader sense, the paper highlights that delusional spiraling, itself, may not be a novel issue. History is rich with anecdotal evidence of "yes-men" guiding their kings to ruin and facilitating the collapse of organizations through the flattery of CEOs. Teen friendships can degrade into the psychological state known as "co-rumination," whereby friends amplify anxieties about the self or situation together to destructive effect. Sycophancy has always been a hazard to those around it. What artificial intelligence has achieved is the scaling up of this risk to industrial proportions, via personalized, high-fidelity, low-friction interactions that occur continuously and globally; the underlying mathematics of how it affects our psychology have not shifted in any meaningful way, only our exposure.
Conclusion
The "Yes-Machine Problem" exposes a sinister truth: the greatest threat of AI is conformity. Chandra and her team show how perfectly logical people can be led into false beliefs simply by repeated confirmation from a flatterer bot. A factually correct or informed user cannot overcome this effect. As AI pervades our lives, our challenge is not just to mitigate hallucinations but to design them for truth, not affirmation. Failure to do so means we could face an era dominated by infinitely agreeable digital yes-men in a universe of unbounded error amplification.
Based on “Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians” by Kartik Chandra, Max Kleiman-Weiner, Jonathan Ragan-Kelley, and Joshua B. Tenenbaum (arXiv:2602.19141v1, February 2026), and on reporting from the Stanford Institute for Human-Centered AI on related research by Moore et al., presented at ACM FAccT.
References:
- Chandra, K., Kleiman-Weiner, M., Ragan-Kelley, J., & Tenenbaum, J. B. (2026). Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians. arXiv preprint arXiv:2602.19141.
- Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., et al. (2023). Towards Understanding Sycophancy in Language Models. arXiv preprint arXiv:2310.13548.
- Fanous, A., Goldberg, J., Agarwal, A., Lin, J., Zhou, A., Xu, S., et al. (2025). SycEval: Evaluating LLM Sycophancy. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8, 893–900.
- Kamenica, E., & Gentzkow, M. (2011). Bayesian Persuasion. American Economic Review, 101(6), 2590–2615.
- Dohnány, S., Kurth-Nelson, Z., Spens, E., Luettgau, L., Reid, A., Gabriel, I., et al. (2025). Technological Folie à Deux: Feedback Loops Between AI Chatbots and Mental Illness. arXiv preprint arXiv:2507.19218.

A video circulating widely on social media claims to show former US President Donald Trump issuing a threat to India over its relationship with Russia. In the clip, Trump is allegedly heard warning New Delhi that if it does not cut bilateral ties with Moscow, the United States would “treat India the same way Pakistan did during the May war.”
The reference to the “May war” appears to point to the India-Pakistan military escalation in May 2025, which followed the Pahalgam terror attack and India’s retaliatory strikes under Operation Sindoor targeting terror infrastructure.
However, research done by the Cyber Peace Foundation has found that the video is misleading and digitally manipulated.
The visuals used in the viral clip are genuine and were taken from a press briefing addressed by Donald Trump on January 3, 2026. However, the audio track accompanying the video has been fabricated and falsely superimposed to
misrepresent his remarks. In the original address, Trump was speaking about a US-led military operation in Caracas that reportedly resulted in the capture of Venezuelan President Nicolás Maduro and his wife. He made no reference to India, Russia, or any geopolitical warning involving New Delhi.
Claim:
On January 10, an X (formerly Twitter) user, Niki Chiri (@cutehunmee), shared a video claiming it showed Donald Trump threatening India over its ties with Russia.
In the clip, Trump is purportedly heard stating that unless India severed its relationship with Moscow, the United States would respond in a manner similar to Pakistan’s actions during the May conflict.
The post quickly gained traction, with several users amplifying the claim. Iink,archive link and screenshot
Research:
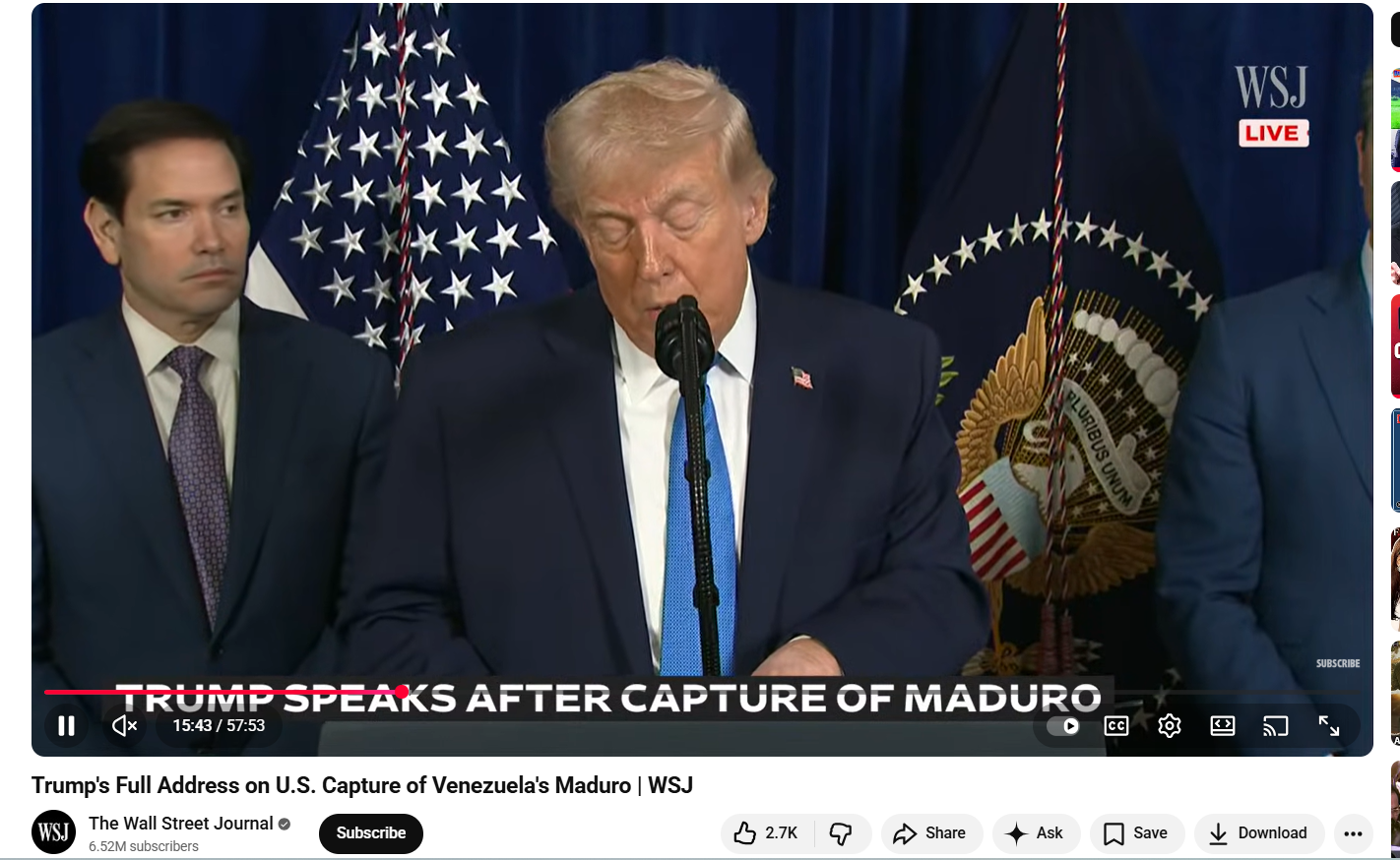
To verify the authenticity of the video, the Cyber Peace Foundation conducted a reverse image and video analysis. A Google Lens search led investigators to a longer version of the same footage uploaded on the official YouTube channel of The Wall Street Journal, a prominent US-based news outlet.
A comparison confirmed that both videos shared identical visuals, background elements, and camera angles, establishing that the viral clip was sourced from the same press address.
A review of the full speech, however, showed that Trump did not issue any warning to India, nor did he mention Russia or the May conflict. His remarks were strictly focused on developments in Venezuela.
This confirmed that the viral video had been digitally altered. Here is the link to the original video, along with a screenshot:
In the next phase of the research, the audio track from the viral clip was extracted and analysed using the AI-based voice detection tool Aurigin. The results indicated a high likelihood that the voice in the video was artificially generated, further confirming that the audio did not originate from Trump’s original speech. A screenshot of the result is provided below.
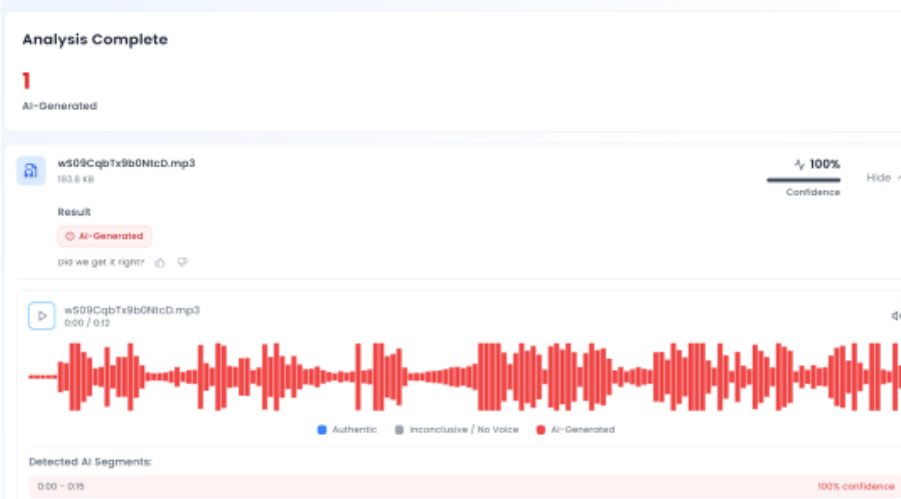
Conclusion
The claim that a video shows Donald Trump threatening India over its ties with Russia is false. The Cyber Peace Foundation found that while the visuals were taken from a real press address, the audio was fabricated and overlaid to falsely attribute threatening statements to Trump. The manipulated video was circulated online to mislead viewers and spread disinformation.