Taming Bias in AI: Statistical Principles, Fairness-Aware Algorithms and Why It Matters
Artificial intelligence is revolutionizing industries such as healthcare to finance to influence the decisions that touch the lives of millions daily. However, there is a hidden danger associated with this power: unfair results of AI systems, reinforcement of social inequalities, and distrust of technology. One of the main causes of this issue is training data bias, which appears when the examples on which an AI model is trained are not representative or skewed. To deal with it successfully, this needs a combination of statistical methods, algorithmic design that is mindful of fairness, and robust governance over the AI lifecycle. This article discusses the origin of bias, the ways to reduce it, and the unique position of fairness-conscious algorithms.
Why Bias in Training Data Matters
The bias in AI occurs when the models mirror and reproduce the trends of inequality in the training data. When a dataset has a biased representation of a demographic group or includes historical biases, the model will be trained to make decisions in ways that will harm the group. This is a fact that has a practical implication: prejudiced AI may cause discrimination during the recruitment of employees, lending, and evaluation of criminal risks, as well as various other spheres of social life, thus compromising justice and equity. These problems are not only technical in nature but also require moral principles and a system of governance (E&ICTA).
Bias is not uniform. It may be based on the data itself, the algorithm design, or even the lack of diversity among developers. The bias in data occurs when data does not represent the real world. Algorithm bias may arise when design decisions inadvertently put one group at an unfair advantage over another. Both the interpretation of the model and data collection may be affected by human bias. (MDPI)
Statistical Principles for Reducing Training Data Bias
Statistical principles are at the core of bias mitigation and they redefine the data-model interaction. These approaches are focused on data preparation, training process adjustment, and model output corrections in such a way that the notion of fairness becomes a quantifiable goal.
Balancing Data Through Re-Sampling and Re-Weighting
Among the aforementioned methods, a fair representation of all the relevant groups in the dataset is one way. This can be achieved by oversampling underrepresented groups and undersampling overrepresented groups. Oversampling gives greater weight to minority examples, whereas re-weighting gives greater weight to under-represented data points in training. The methods minimize the tendency of models to fit to salient patterns and improve coverage among vulnerable groups. (GeeksforGeeks)
Feature Engineering and Data Transformation
The other statistical technique is to convert data characteristics in such a way that sensitive characteristics have a lesser impact on the results. In one example, fair representation learning adjusts the data representation to discourage bias during the untraining of the model. The disparate impact remover adjust technique performs the adjustment of features of the model in such a way that the impact of sensitive features is reduced during learning. (GeeksforGeeks)
Measuring Fairness With Metrics
Statistical fairness measures are used to measure the effectiveness of a model in groups.
Fairness-Aware Algorithms Explained
Fair algorithms do not simply detect bias. They incorporate fairness goals in model construction and run in three phases including pre-processing, in-processing, and post-processing.
Pre-Processing Techniques
Fairness-aware pre-processing deals with bias prior to the model consuming the information. This involves the following ways:
- Rebalancing training data through sampling and re-weighting training data to address sample imbalances.
- Data augmentation to generate examples of underrepresented groups.
- Feature transformation removes or downplays the impact of sensitive attributes prior to the commencement of training. (IJMRSET)
These methods can be used to guarantee that the model is trained on more balanced data and to reduce the chances of bias transfer between historical data.
In-Processing Techniques
The in-processing techniques alter the learning algorithm. These include:
- Fairness constraints that penalize the model for making biased predictions during training.
- Adversarial debiasing, where a second model is used to ensure that sensitive attributes are not predicted by the learned representations.
- Fair representation learning that modifies internal model representations in favor of
Post-Processing Techniques
Fairness may be enhanced after training by changing the model outputs. These strategies comprise:
- Threshold adjustments to various groups to meet conditions of fairness, like equalized odds.
- Calibration techniques such that the estimated probabilities are fair indicators of the actual probabilities in groups. (GeeksforGeeks)
Challenges
Mitigating bias is complex. The statistical bias minimization may at times come at the cost of the model accuracy, and there is a conflict between predictive performance and fairness. The definition of fairness itself is potentially a difficult task because various applications of fairness require various criteria, and various criteria can be conflicting. (MDPI)
Gaining varied and representative data is also a challenge that is experienced because of privacy issues, incomplete records, and a lack of resources. The auditing and reporting done on a continuous basis are needed so that mitigation processes are up to date, as models are continually updated. (E&ICTA)
Why Fairness-Aware Development Matters
The outcomes of the unfair treatment of some groups by AI systems are far-reaching. Discriminatory software in recruitment may support inequality in the workplace. Subjective credit rating may deprive deserving people of opportunities. Unbiased medical forecasts might result in the flawed allocation of medical resources. In both cases, prejudice contravenes the credibility and clouds the greater prospect of AI. (E&ICTA)
Algorithms that are fair and statistical mitigation plans provide a way to create not only powerful AI but also fair and trustworthy AI. They admit that the results of AI systems are social tools whose effects extend across society. Responsible development will necessitate sustained fairness quantification, model adjustment, and upholding human control.
Conclusion
AI bias is not a technical malfunction. It is a mirror of real-world disparities in data and exaggerated by models. Statistical rigor, wise algorithm design, and readiness to address the trade-offs between fairness and performance are required to reduce training data bias. Fairness-conscious algorithms (which can be implemented in pre-processing, in-processing, or post-processing) are useful in delivering more fair results. As AI is taking part in the most crucial decisions, it is necessary to consider fairness at the beginning to have a system that serves the population in a responsible and fair manner.
References
- Understanding Bias in Artificial Intelligence: Challenges, Impacts, and Mitigation Strategies: E&ICTA, IITK
- Bias and Fairness in Artificial Intelligence: Methods and Mitigation Strategies: JRPS Shodh Sagar
- Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies: MDPI
- Ensuring Fairness in Machine Learning Algorithms: GeeksforGeeks
Bias and Fairness in Machine Learning Models: A Critical Examination of Ethical Implications: IJMRSET - Bias in AI Models: Origins, Impact, and Mitigation Strategies: Preprints
- Bias in Artificial Intelligence and Mitigation Strategies: TCS
- Survey on Machine Learning Biases and Mitigation Techniques: MDPI
Related Blogs
.webp)
Introduction
The automobile business is fast expanding, with vehicles becoming sophisticated, interconnected gadgets equipped with cutting-edge digital technology. This integration improves convenience, safety, and efficiency while also exposing automobiles to a new set of cyber risks. Electric vehicles (EVs) are equipped with sophisticated computer systems that manage various functions, such as acceleration, braking, and steering. If these systems are compromised, it could result in hazardous situations, including the remote control of the vehicle or unauthorized access to sensitive data. The automotive sector is evolving with the rise of connected car stakeholders, exposing new vulnerabilities for hackers to exploit.
Why Automotive Cybersecurity is required
Cybersecurity threats to automotives result from hardware, software and overall systems redundancy. Additional concerns include general privacy clauses that justify collecting and transferring data to “third-party vendors”, without explicitly disclosing who such third parties are and the manner of processing personal data. For example, infotainment platform data may show popular music and the user’s preferences, which may be used by the music industry to improve marketing strategies. Similarly, it is lesser known that any data relating to behavioural tracking data, such as driving patterns etc., are also logged by the original equipment manufacturer.
Hacking is not limited to attackers gaining control of an electronic automobile; it includes malicious actors hacking charging stations to manipulate the systems. In Russia, EV charging stations were hacked in Moscow to display pro-Ukraine and anti-Putin messages such as “Glory to Ukraine” and “Death to the enemy” in the backdrop of the Russia-Ukraine war. Other examples include instances from the Isle of Wight, where hackers controlled the EV monitor to show inappropriate content and display high voltage fault codes to EV owners, preventing them from charging their vehicles with empty batteries.
UN Economic Commission for Europe releases Regulation 155 for Automobiles
UN Economic Commission for Europe Regulation 155 lays down uniform provisions concerning the approval of vehicles with regard to cybersecurity and cybersecurity management systems (CSMS). This was originally a part of the Commission.s Work Paper (W.P.) 29 that aimed to harmonise vehicular regulations for vehicles and vehicle equipment. Regulation 155 has a two-prong objective; first, to ensure cybersecurity at the organisational level and second, to ensure adequate designs of the vehicle architecture. A critical aspect in this context is the implementation of a certified CSMS by all companies that bring vehicles to market. Notably, this requirement alters the perspective of manufacturers; their responsibilities no longer conclude with the start of production (SOP). Instead, manufacturers are now required to continuously monitor and assess the safety systems throughout the entire life cycle of a vehicle, including making any necessary improvements.
This Regulation reflects the highly dynamic nature of software development and assurance. Moreover, the management system is designed to ensure compliance with safety requirements across the entire supply chain. This is a significant challenge, considering that suppliers currently account for over 70 per cent of the software volume.
The Regulation, which is binding in nature for 64 member countries, came into force in 2021. UNECE countries were required to be compliant with the Regulations by July 2022 for all new vehicles and by July 2024, the Regulation was set to apply to all vehicles. It is believed that the Regulation will become a de facto global standard, since vehicles authorised in a particular country may not be brought into the global market or the market of any UNECE member country based on any other authorisation. In such a scenario, OEMs of non-member countries may be required to give a “self-declaration”, declaring the equipment’s conformity with cybersecurity standards.
Conclusion
To compete and ensure trust, global car makers must deliver a robust cybersecurity framework that meets evolving regulations. The UNECE regulations in this regard are driving this direction by requiring automotive original equipment manufacturers (OEMs) to integrate vehicle cybersecurity throughout the entire value chain. The ‘security by design' approach aims to build a connected car that is trusted by all. Automotive cybersecurity involves measures and technologies to protect connected vehicles and their onboard systems from growing digital threats.
References:
- “Electric vehicle cyber security risks and best practices (2023)”, Cyber Talk, 1 August 2023. https://www.cybertalk.org/2023/08/01/electric-vehicle-cyber-security-risks-and-best-practices-2023/#:~:text=EVs%20are%20equipped%20with%20complex,unauthorized%20access%20to%20sensitive%20data.
- Gordon, Aaron, “Russian Electric Vehicle Chargers Hacked, Tell Users “PUTIN IS A D*******D”, Vice, 28 February 2022. https://www.vice.com/en/article/russian-electric-vehicle-chargers-hacked-tell-users-putin-is-a-dickhead/
- “Isle of Wight: Council’s electric vehicle chargers hacked to show porn site”, BBC, 6 April 2022. https://www.bbc.com/news/uk-england-hampshire-61006816
- Sandler, Manuel, “UN Regulation No. 155: What You Need to Know about UN R155”, Cyres Consulting, 1 June 2022. https://www.cyres-consulting.com/un-regulation-no-155-requirements-what-you-need-to-know/?srsltid=AfmBOopV1pH1mg6M2Nn439N1-EyiU-gPwH2L4vq5tmP0Y2vUpQR-yfP7#A_short_overview_Background_knowledge_on_UN_Regulation_No_155
- https://unece.org/wp29-introduction?__cf_chl_tk=ZYt.Sq4MrXvTwSiYURi_essxUCGCysfPq7eSCg1oXLA-1724839918-0.0.1.1-13972

Executive Summary
Amid reports of a two-week ceasefire announced on April 8, 2026, between the United States and Iran, a video showing a sudden explosion inside a building has gone viral on social media. The clip shows a fire brigade vehicle stationed outside a structure, with people entering the premises moments before a blast occurs. Social media users are sharing the video with claims that Iran carried out an attack on Israeli Defence Minister Yoav Gallant, alleging that the building shown is linked to Israel’s defence ministry.
However, a research by CyberPeace has found the claim to be false. The viral video is not recent and has no connection to Israel or any ongoing conflict.
Claim
A Facebook user shared the video on April 3, 2026, claiming that Iran had attacked Israeli Defence Minister Yoav Gallant and severely damaged a building associated with him.
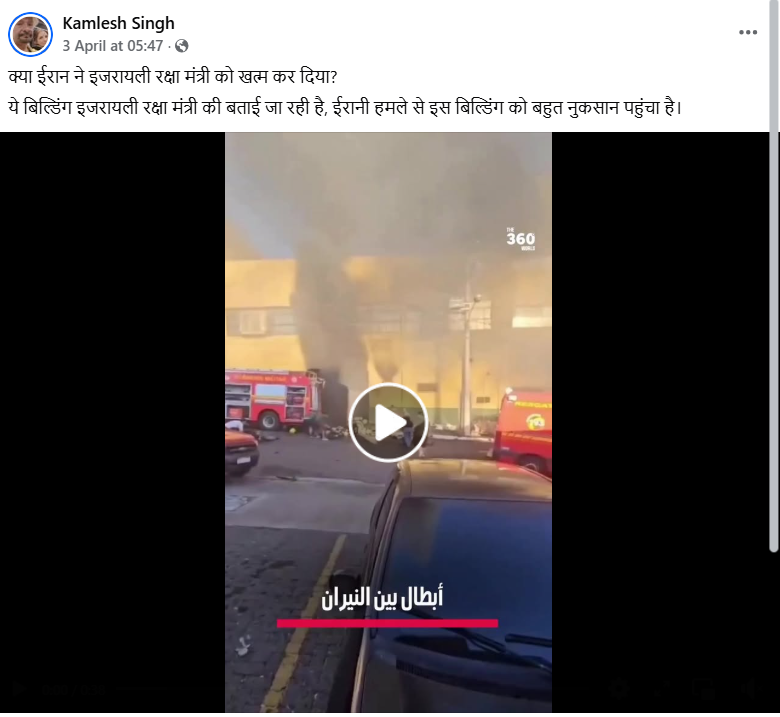
Fact Check
To verify the claim, we extracted keyframes from the viral video and conducted a reverse image search. This led us to the same video posted on an X account named Fernanda Melchionna on December 31, 2025.
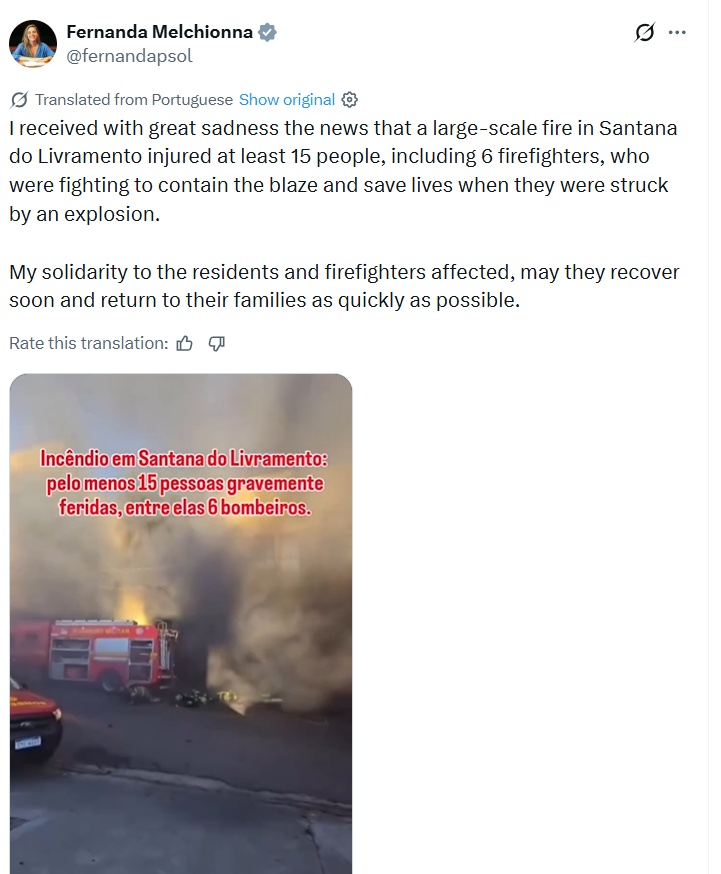
According to the available information, the video is from Santana do Livramento, where a major fire broke out in a supermarket. Further keyword searches led us to a report published on December 31, 2025, by the Brazilian news website GZH (gaúcha zh clicrbs). The report stated that a fire had erupted in a supermarket in Santana do Livramento, and firefighters had reached the spot to control the blaze. During the operation, an explosion occurred, leaving around 17 people injured. The injured were later taken to a hospital.

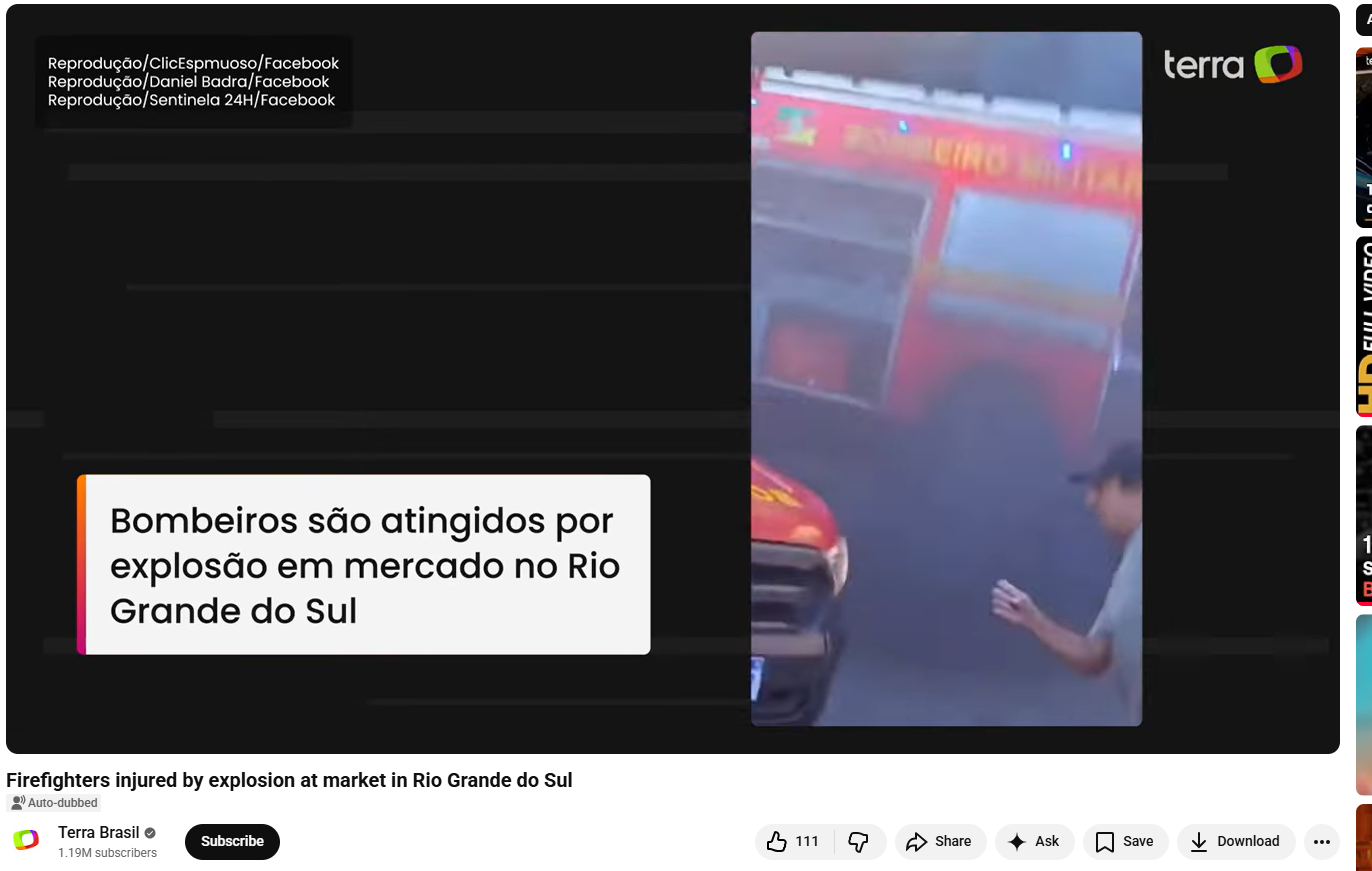
We also found the same video uploaded on the YouTube channel Terra Brasil on January 1, 2026, further confirming its origin and timeline.
Conclusion
The viral claim is false and misleading. The explosion video being shared as an attack on Israeli Defence Minister Yoav Gallant is unrelated to the ongoing Middle East situation. The footage is actually from December 2025 and shows an incident in Brazil, where a fire in a supermarket led to an explosion during firefighting operations. There is no evidence to suggest any such attack took place in Israel. The video has been taken out of context and circulated with a fabricated narrative to mislead users and exploit geopolitical tensions.

Introduction
Charity and donation scams have continued to persist and are amplified in the digital era, where messages spread rapidly through WhatsApp, emails, and social media. These fraudulent schemes involve threat actors impersonating legitimate charities, government appeals, or social causes to solicit funds. Apart from targeting the general public, they also impact entities such as reputable tech firms and national institutions. Victims are tricked into transferring money or sharing personal information, often under the guise of urgent humanitarian efforts or causes.
A recent incident involves a fake WhatsApp message claiming to be from the Indian Ministry of Defence. The message urged users to donate to a fund for “modernising the Indian Army.” The government later confirmed this message was entirely fabricated and part of a larger scam. It emphasised that no such appeal had been issued by the Ministry, and urged citizens to verify such claims through official government portals before responding.
Tech Industry and Donation-Related Scams
Large corporations are also falling prey. According to media reports, an American IT company recently terminated around 700 Indian employees after uncovering a donation-related fraud. At least 200 of them were reportedly involved in a scheme linked to Telugu organisations in the US. The scam echoed a similar situation that had previously affected Apple, where Indian employees were fired after being implicated in donation fraud tied to the Telugu Association of North America (TANA). Investigations revealed that employees had made questionable donations to these groups in exchange for benefits such as visa support or employment favours.
Common People Targeted
While organisational scandals grab headlines, the common man remains equally or even more vulnerable. In a recent incident, a man lost over ₹1 lakh after clicking on a WhatsApp link asking for donations to a charity. Once he engaged with the link, the fraudsters manipulated him into making repeated transfers under various pretexts, ranging from processing fees to refund-related transactions (social engineering). Scammers often employ a similar set of tactics using urgency, emotional appeal, and impersonation of credible platforms to convince and deceive people.
Cautionary Steps
CyberPeace recommends adopting a cautious and informed approach when making charitable donations, especially online. Here are some key safety measures to follow:
- Verify Before You Donate. Always double-check the legitimacy of donation appeals. Use official government portals or the official charities' websites. Be wary of unfamiliar phone numbers, email addresses, or WhatsApp forwards asking for money.
- Avoid Clicking on Suspicious Links
Never click on links or download attachments from unknown or unverified sources. These could be phishing links/ malware designed to steal your data or access your bank accounts. - Be Sceptical of Urgency Scammers bank on creating a false sense of urgency to pressure their victims into donating quickly. One must take the time to evaluate before responding.
- Use Secure Payment Channels Ensure that one makes donations only through platforms that are secure, trusted, and verified. These include official UPI handles, government-backed portals (like PM CARES or Bharat Kosh), among others.
- Report Suspected Fraud In case one receives suspicious messages or falls victim to a scam, they are encouraged to report it to cybercrime authorities via cybercrime.gov.in (1930) or the local police, as prompt reporting can prevent further fraud.
Conclusion
Charity should never come at the cost of trust and safety. While donating to a good cause is noble, doing it mindfully is essential in today’s scam-prone environment. Always remember: a little caution today can save a lot tomorrow.
References
- https://economictimes.indiatimes.com/news/defence/misleading-message-circulating-on-whatsapp-related-to-donation-for-armys-modernisation-govt/articleshow/120672806.cms?from=mdr
- https://timesofindia.indiatimes.com/technology/tech-news/american-company-sacks-700-of-these-200-in-donation-scam-related-to-telugu-organisations-similar-to-firing-at-apple/articleshow/120075189.cms
- https://timesofindia.indiatimes.com/city/hyderabad/apple-fires-some-indians-over-donation-fraud-tana-under-scrutiny/articleshow/117034457.cms
- https://www.indiatoday.in/technology/news/story/man-gets-link-for-donation-and-charity-on-whatsapp-loses-over-rs-1-lakh-after-clicking-on-it-2688616-2025-03-04