#FactCheck: An image shows Sunita Williams with Trump and Elon Musk post her space return.
Executive Summary:
Our research has determined that a widely circulated social media image purportedly showing astronaut Sunita Williams with U.S. President Donald Trump and entrepreneur Elon Musk following her return from space is AI-generated. There is no verifiable evidence to suggest that such a meeting took place or was officially announced. The image exhibits clear indicators of AI generation, including inconsistencies in facial features and unnatural detailing.
Claim:
It was claimed on social media that after returning to Earth from space, astronaut Sunita Williams met with U.S. President Donald Trump and Elon Musk, as shown in a circulated picture.

Fact Check:
Following a comprehensive analysis using Hive Moderation, the image has been verified as fake and AI-generated. Distinct signs of AI manipulation include unnatural skin texture, inconsistent lighting, and distorted facial features. Furthermore, no credible news sources or official reports substantiate or confirm such a meeting. The image is likely a digitally altered post designed to mislead viewers.

While reviewing the accounts that shared the image, we found that former Indian cricketer Manoj Tiwary had also posted the same image and a video of a space capsule returning, congratulating Sunita Williams on her homecoming. Notably, the image featured a Grok watermark in the bottom right corner, confirming that it was AI-generated.

Additionally, we discovered a post from Grok on X (formerly known as Twitter) featuring the watermark, stating that the image was likely AI-generated.
Conclusion:
As per our research on the viral image of Sunita Williams with Donald Trump and Elon Musk is AI-generated. Indicators such as unnatural facial features, lighting inconsistencies, and a Grok watermark suggest digital manipulation. No credible sources validate the meeting, and a post from Grok on X further supports this finding. This case underscores the need for careful verification before sharing online content to prevent the spread of misinformation.
- Claim: Sunita Williams met Donald Trump and Elon Musk after her space mission.
- Claimed On: Social Media
- Fact Check: False and Misleading
Related Blogs

Introduction
In a major policy shift aimed at synchronizing India's fight against cyber-enabled financial crimes, the government has taken a landmark step by bringing the Indian Cyber Crime Coordination Centre (I4C) under the ambit of the Prevention of Money Laundering Act (PMLA). In the notification released in the official gazette on 25th April, 2025, the Department of Revenue, Ministry of Finance, included the Indian Cyber Crime Coordination Centre (I4C) under Section 66 of the Prevention of Money Laundering Act, 2002 (hereinafter referred to as “PMLA”). The step comes as a significant attempt to resolve the asynchronous approach of different agencies (Enforcement Directorate (ED), State Police, CBI, CERT-In, RBI) set up under the government responsible for preventing and often possessing key information regarding cyber crimes and financial crimes. As it is correctly put, "When criminals sprint and the administration strolls, the finish line is lost.”
The gazetted notification dated 25th April, 2025, read as follows:
“In exercise of the powers conferred by clause (ii) of sub-section (1) of section 66 of the Prevention of Money-laundering Act, 2002 (15 of 2003), the Central Government, on being satisfied that it is necessary in the public interest to do so, hereby makes the following further amendment in the notification of the Government of India, in the Ministry of Finance, Department of Revenue, published in the Gazette of India, Extraordinary, Part II, section 3, sub-section (i) vide number G.S.R. 381(E), dated the 27th June, 2006, namely:- In the said notification, after serial number (26) and the entry relating thereto, the following serial number and entry shall be inserted, namely:— “(27) Indian Cyber Crime Coordination Centre (I4C).”.
Outrunning Crime: Strengthening Enforcement through Rapid Coordination
The usage of cyberspace to commit sophisticated financial crimes and white-collar crimes is a one criminal parallel passover that no one was looking forward to. The disenchanted reality of today’s world is that the internet is used for as much bad as it is for good. The internet has now entered the financial domain, facilitating various financial crimes. Money laundering is a financial crime that includes all processes or activities that are in connection with the concealment, possession, acquisition, or use of proceeds of crime and projecting it as untainted money. In the offence of money laundering, there is an intricate web and trail of financial transactions that are hard to track, as they are, and with the advent of the internet, the transactions are often digital, and the absence of crucial information hampers the evidentiary chain. With this new step, the Enforcement Directorate (ED) will now make headway into the investigation with the information exchange under PMLA from and to I4C, removing the obstacles that existed before this notification.
Impact
The decision of the finance ministry has to be seen in terms of all that is happening around the globe, with the rapid increase in sophisticated financial crimes. By formally empowering the I4C to share and receive information with the Enforcement Directorate under PMLA, the government acknowledges the blurred lines between conventional financial crime and cybercrime. It strengthens India’s financial surveillance, where money laundering and cyber fraud are increasingly two sides of the same coin. The assessment of the impact can be made from the following facilitations enabled by the decision:
- Quicker internet detection of money laundering
- Money trail tracking in real time across online platforms
- Rapid freeze of cryptocurrency wallets or assets obtained fraudulently
Another important aspect of this decision is that it serves as a signal that India is finally equipping itself and treating cyber-enabled financial crimes with the gravitas that is the need of the hour. This decision creates a two-way intelligence flow between cybercrime detection units and financial enforcement agencies.
Conclusion
To counter the fragmented approach in handling cyber-enabled white-collar crimes and money laundering, the Indian government has fortified its legal and enforcement framework by extending PMLA’s reach to the Indian Cyber Crime Coordination Centre (I4C). All the decisions and the brainstorming that led up to this notification are crucial at this point in time for the cybercrime framework that India needs to be on par with other countries. Although India has come a long way in designing a robust cybercrime intelligence structure, as long as it excludes and works in isolation, it will be ineffective. So, the current decision in discussion should only be the beginning of a more comprehensive policy evolution. The government must further integrate and devise a separate mechanism to track “digital footprints” and incorporate a real-time red flag mechanism in digital transactions suspected to be linked to laundering or fraud.

Executive Summary
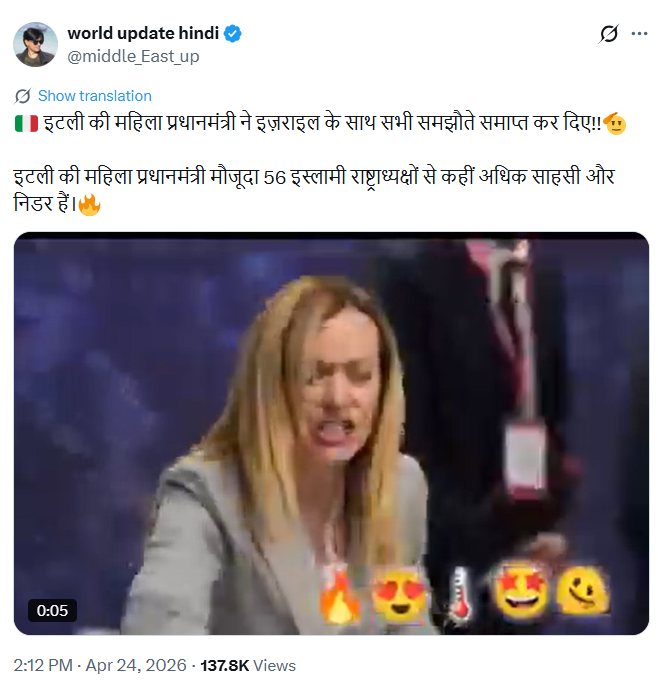
A video purportedly showing Italian Prime Minister Giorgia Meloni angrily addressing a room full of delegates before throwing a bundle of papers and storming out has gone viral on social media. The clip is being shared alongside claims that Meloni terminated all agreements with Israel following growing tensions over the conflict in the Middle East. However, CyberPeace Research Wing research found that the viral video is not authentic. The clip was generated using Artificial Intelligence (AI).
Claim
On April 24, 2026, an X user shared the viral video with the caption:“Italy's woman Prime Minister has terminated all agreements with Israel!! Italy's woman Prime Minister is far more courageous and fearless than the leaders of 56 Islamic nations.”
- https://x.com/middle_East_up/status/2047597154257297878?s=20
- https://perma.cc/4EM9-5GS4
Fact Check
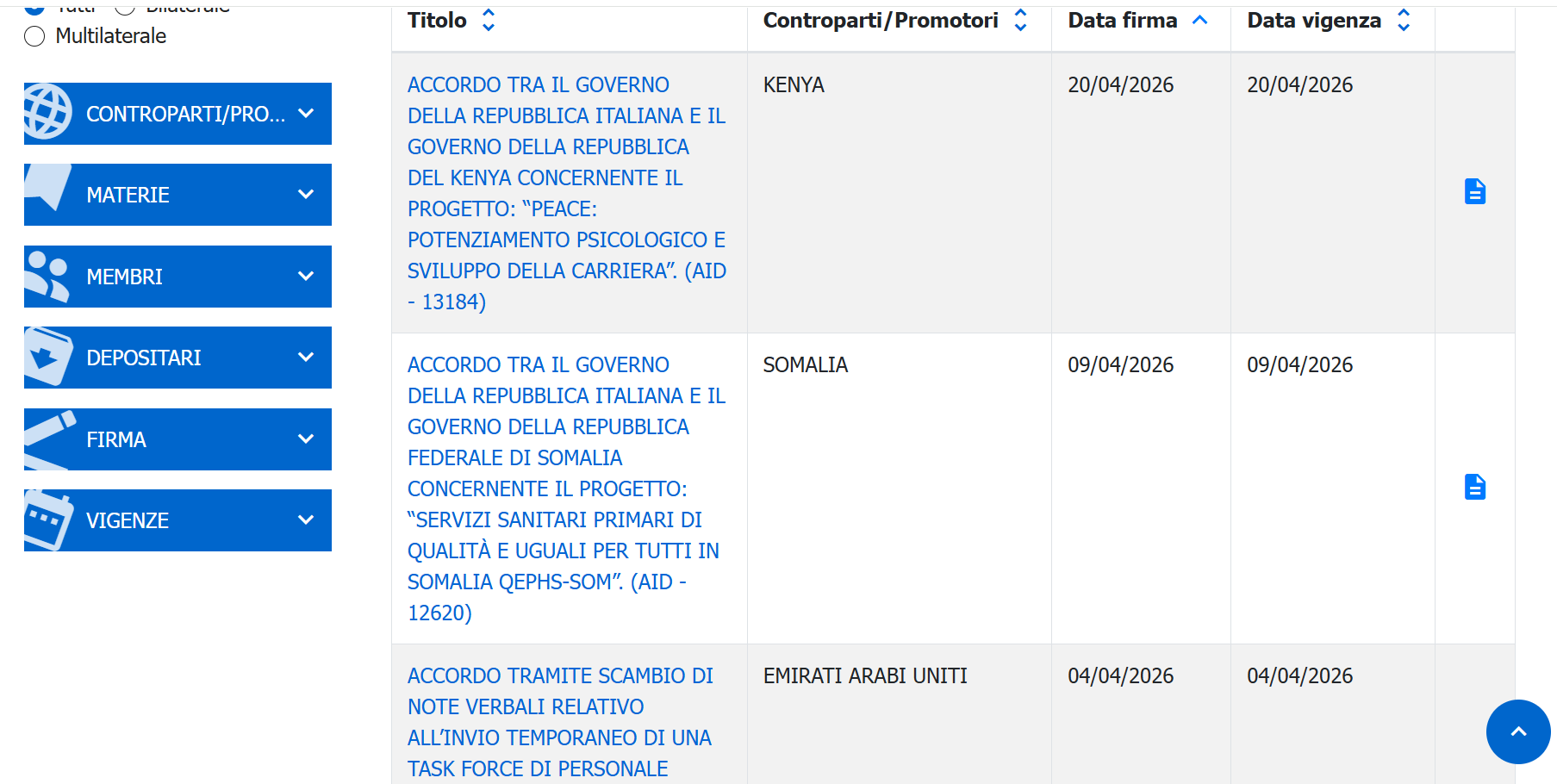
To verify the claim, we examined official records related to agreements between Italy and Israel. Data available from the Italian Ministry of Foreign Affairs and International Cooperation shows that multiple bilateral agreements between the two countries remain in force in 2026.
- https://atrio.esteri.it/Home/Search
Further research found reports related to discussions within the European Union regarding the suspension of certain cooperation arrangements with Israel. During a meeting of EU foreign ministers in Luxembourg, Spain and Ireland renewed calls to review the EU-Israel Association Agreement. However, Italian Foreign Minister Antonio Tajani reportedly stated that no decision would be taken that day. A closer examination of the viral clip revealed several visual inconsistencies commonly associated with AI-generated content, including unnatural facial movements, irregular body gestures, and unrealistic scene transitions.
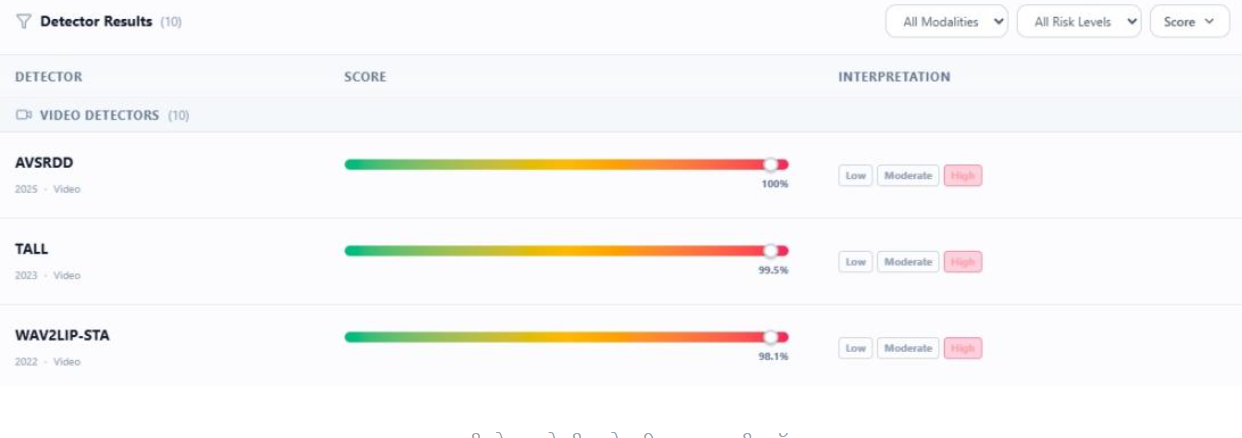
To further verify the footage, we analysed it using the DeepFake-o-Meter tool. Results from three separate detection models indicated that the video was likely generated using artificial intelligence.
Conclusion
CyberPeace Research Wing research found that the viral video allegedly showing Italian Prime Minister Giorgia Meloni angrily terminating agreements with Israel is AI-generated. There is no evidence that the incident shown in the clip actually occurred.

Executive Summary
A video showing a large crowd disrespecting the Indian tricolor along with American and Israeli flags is being widely shared on social media. Users sharing the video claim that the incident recently took place in Iran's capital, Tehran, showcasing "Iran's hatred towards India." However, a fact-check done by the CyberPeace Research Wing has revealed that this claim is misleading. The viral video was not filmed in Iran, but rather during a procession in Karachi, Pakistan.
The Claim
A user on the social media platform X (formerly Twitter) shared the video with the caption: "India’s biggest enemy is burning our flag and guess who is sitting silently? Iran is not our friend. Their hatred towards India is clearly visible, but our tricolor is being burnt in Iran." https://x.com/bhagwakrantivir/status/2071096021183246667 , https://archive.ph/6mGE8

Factcheck
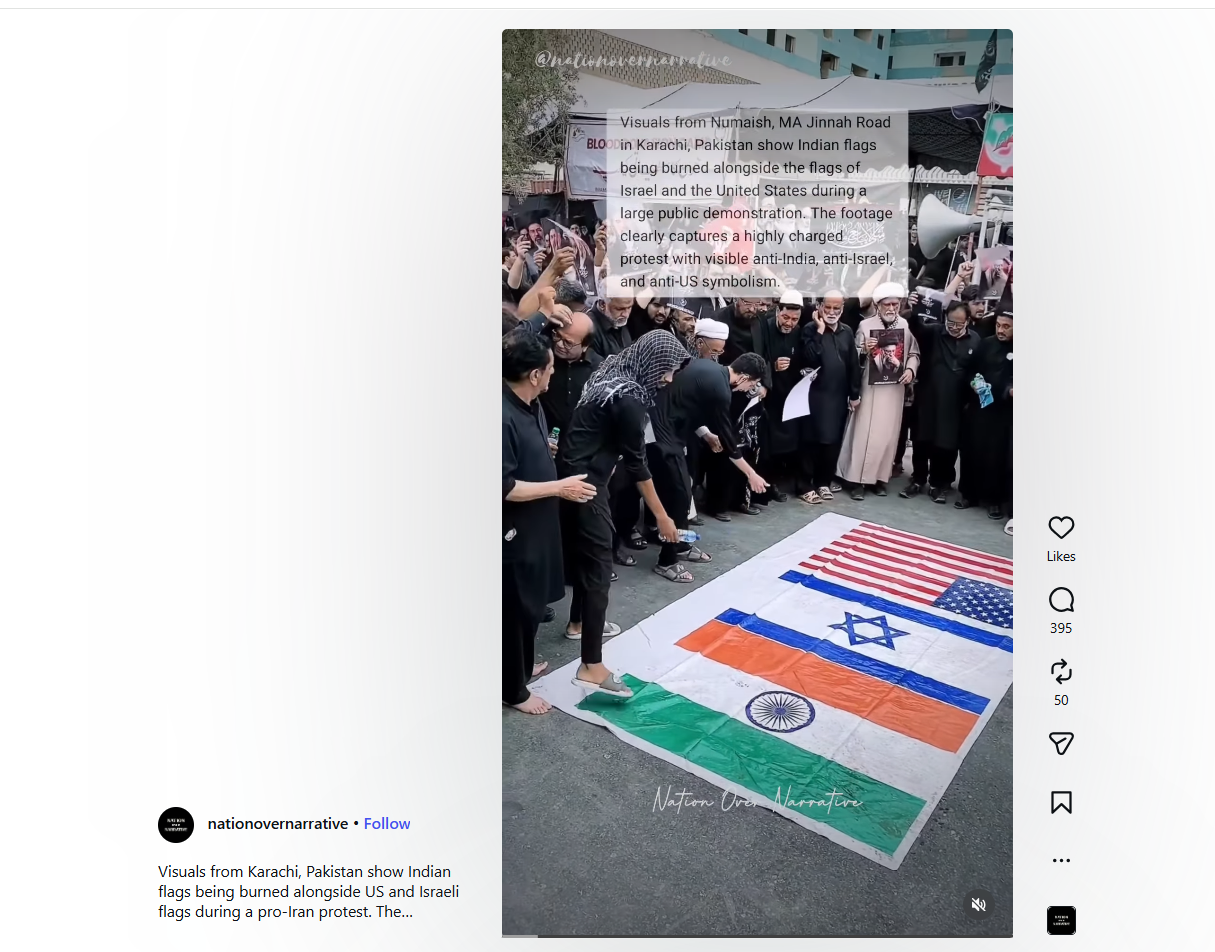
Keyframes extracted from the viral video were searched using Google Lens. This led to an Instagram post containing the exact same footage. The caption of this post identified the location as Karachi, Pakistan, noting that the demonstration was held in support of Iran, during which flags of India, the US, and Israel were burnt.
https://www.instagram.com/reels/DaDLQO6obcK/
Further keyword searches led to the official Instagram account of the 'Imamia Students Organization Karachi'. A video uploaded on June 25, 2026, showed the same event captured from a different camera angle. According to the caption, the footage is from a '9th Muharram' procession in Karachi.
https://www.instagram.com/p/DaApSBfIpNQ/
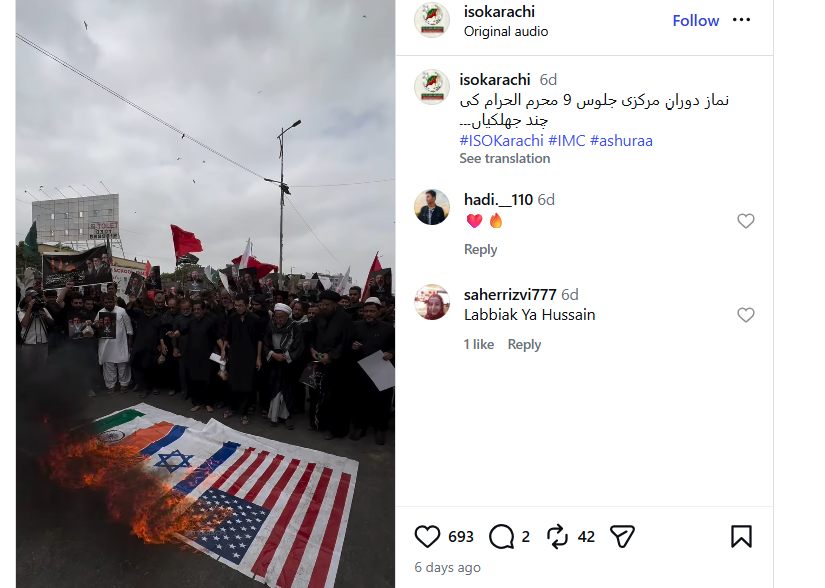
To conclusively establish the location, Google Maps Street View was used to cross-reference the physical landmarks seen in the video.The visual elements perfectly match Mohammad Ali Jinnah Road in Karachi, Pakistan.A distinct blue building named 'Mid Town', visible in the viral video, matches the Google Street View imagery of the location.

Conclusion
The research confirms that the video showing the burning and desecration of the Indian national flag is from Karachi, Pakistan, and not Tehran, Iran. The social media claims linking this incident to Iran are false and contextually misleading.